Building a Java Recommendation System: Our Why, Tech Stack, and Starting Methodology

 While shopping online, have you ever wondered how Amazon knows your favorite books, makeup, or shoes? Amazon uses a Java recommendation engine (typically with machine learning or artificial intelligence) to suggest products it thinks you would be interested in buying.
While shopping online, have you ever wondered how Amazon knows your favorite books, makeup, or shoes? Amazon uses a Java recommendation engine (typically with machine learning or artificial intelligence) to suggest products it thinks you would be interested in buying.
In other words, “Product recommendation is a filtering system that seeks to predict and show the items a user would like to purchase. It may not be entirely accurate, but it is doing its job right if it shows you what you like.”
A Java recommendation engine has become increasingly popular in recent years and is often used to recommend movies, music, news, books, and other products. They also suggest research articles, search queries, and social tags.
Java Recommendation Engine: Powering Personalized Experiences Beyond E-Commerce
While many of our customers have a B2C component, many uses for recommendations outside e-commerce platforms exist. For example, imagine your company has a large product catalog. You can use a Java recommendation engine to help your sales team find additional services or products to suggest.
With the versatility and potential impact of using a Java recommendation system internally or externally, what better way to showcase our team’s Java skills than to build our very own version. In the remainder of this article, we’ll discuss how to build a recommendation engine and describe some of the supporting technologies we used to develop our Java-based engine and key decisions we’ve made so far.
Supporting Technologies for a Java Recommendation Engine
Java recommendation engines come in all shapes, sizes, and languages. You may often see one engine that works great for e-commerce-based solutions but doesn’t work well when making movie recommendations. When deciding on the ideal engine for our client, we evaluated various well-known technologies and selected the best ones for our needs.
Java vs. Python
When it comes to Java vs. Python, they offer many advantages, but they differ in several ways. Python is one of the world’s most popular programming languages and is easy to learn. Plus, Python doesn’t require a lot of complex programming skills often associated with object-oriented languages.
It’s also the program of choice for building AI and machine learning applications – primarily because of the ease with which it handles mathematical applications.

However, Java contains many strengths as well. Java is a general-purpose programming language that includes many possible integrations and applications. Java is very stable, has lots of resources, libraries, and frameworks, and has a highly robust and long-established user community.
In addition, Java is hard to beat for end-over-end value in building complex enterprise applications. Java is a true workhorse throughout the industry, and it’s maintained an excellent reputation for many years.
Another factor influencing our decision, perhaps the most important for our purposes, is that the client’s project was based in Java. Obviously, we were biased in that direction.
Furthermore, we wanted to demonstrate that Java is an excellent language for building recommendation engines. As we’re discovering, Java is second to none and works as good, if not better, than Python as a Java recommendation engine code base.
Frontend: Angular 7 & Bootstrap
After evaluating several front-end solutions, we decided to build the look and feel of the Java recommendation engine with Angular 7. Our decision was straightforward. We already had experience with Angular, and we found it relatively easy for Java developers to learn it. Unsurprisingly, we selected Bootstrap as our CSS framework.
Data storage: PostgreSQL
After debate amongst our team members, we chose PostgreSQL for our data storage solution. Since complex relationships exist between the client’s product categories and the specifications for each category, we determined that a relational database was well-suited for this project.
A document-based database would require additional processing to search documents to find the ones that included the proper product information, and it would then have to update that information accordingly. Since PostgreSQL has an excellent reputation for reliability, diversity of features, and performance, it was an easy choice. Plus, the database is free.
Database: MongoDB
We predicted that our client’s Java recommendation system would need to gather a lot of information about user activities and interests. Therefore, we also needed to select a document-based database to scale and organize big data quickly and efficiently. Thus, we chose MongoDB, one of the world’s most popular NoSQL databases.
Containerization: Docker
We created a modular approach to make the Java recommendation engine easy to deploy using microservices so numerous dependencies or impacts from other services wouldn’t limit us. Since we were already building our client’s application within a microservices environment, we wanted to build the engine with the same containerized capabilities using Docker.

Kaggle
For the actual "nuts and bolts" of the Java recommendation engine, we leveraged Kaggle. Owned by Google, Kaggle is the world's largest data science community with thousands of ready-made datasets and algorithms. Kaggle saved us significant time since we didn't have to create our own engine from scratch.
TensorFlow
TensorFlow is an open-source, machine-learning library that will enable us to more accurately match specific lists with each other and provide a better Java recommendation system. It requires a math background to understand the inputs and processing of the AI solution, and we’re exploring ways to integrate it into our Java recommendation engine.

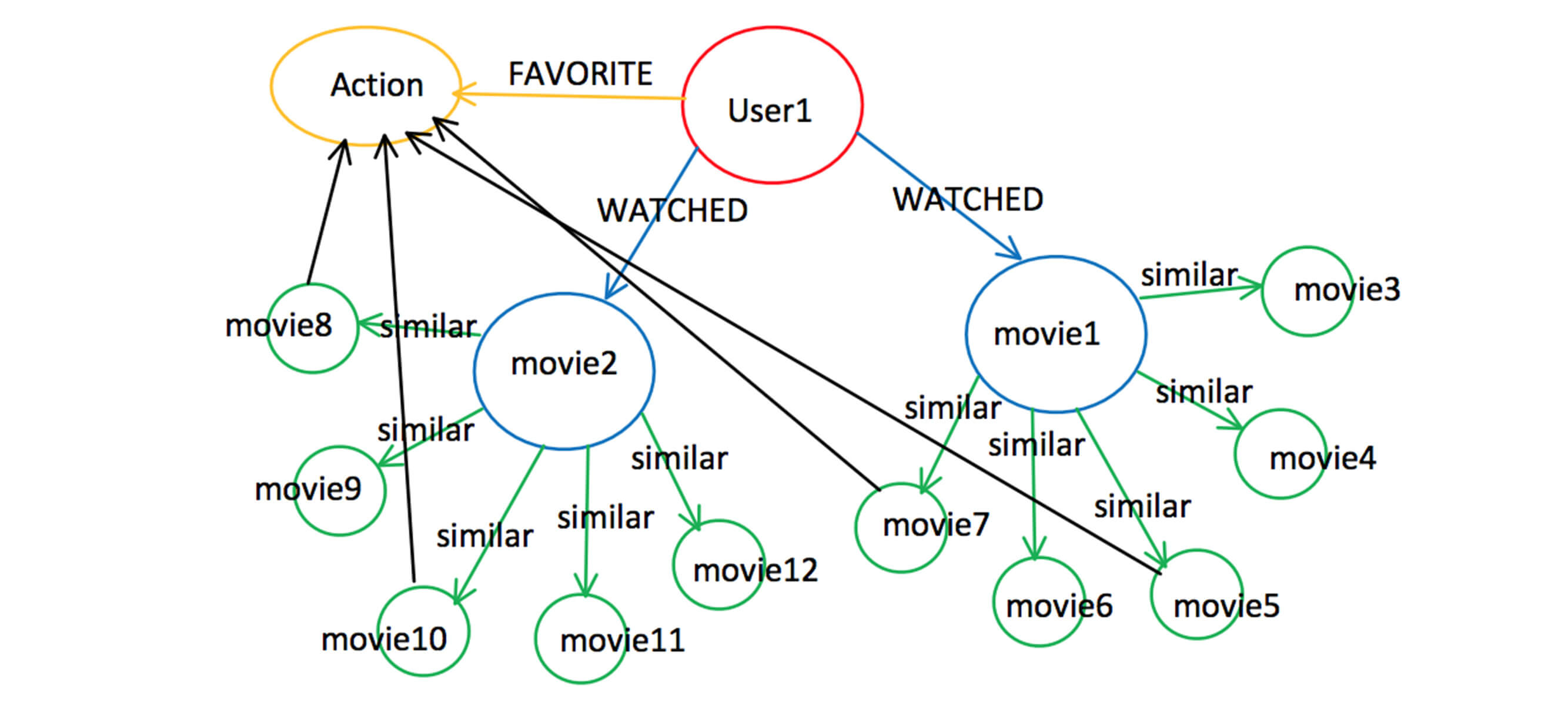
Collaborative Filtering vs. Segmenting Users
While building our Java recommendation engine, we had to choose between two approaches to filtering data: collaborative filtering or user segmentation. Collaborative filtering works by comparing a large group of people to find users who share similar tastes with another user. It compares the items they like and combines them to create a ranked list of suggestions. This approach requires integration with AI and a machine-learning approach called “Deep Learning.”
We eventually decided to use user segmentation as our filtering approach. User segmentation identifies user interests based on unique characteristics, needs, preferences, and tastes. Each user interest is assigned a particular “weight,” which is then used to calculate a recommendation.
For instance, in movie-watching, a user’s watch action has more value than simply adding a movie to their watchlist. Although someone may add a movie to their watchlist 100 times, it will still be discarded from future recommendations if they only watch it once.
For our client’s product catalog, we will segment based on user interest to show suitable product recommendations at the right time. While this approach doesn’t require AI integration, we’d like to eventually adopt a more AI-centric approach to train our applications and improve the Java recommendation engine with the latest machine-learning technologies.

Generic or Customized?
Another question we had to answer was whether to make our Java recommendation engine generic or customized. Our original vision was to build a solution focused specifically on our client’s product catalog.
As things progressed, it became apparent that our approach should be more generic. By doing so, we’d learn more in a short amount of time by not being locked into a specific industry-focused solution.
Therefore, we decided to adopt an already available movie database as our testing ground. This strategy would allow us to extend our learnings across multiple industries instead of focusing on just one specific industry.

Next Steps
Java recommendation engines are prevalent in most industries today, so every tech-savvy business owner, especially those in the e-commerce industry, should consider adding one to their company website.
When we first agreed to build a Java recommendation engine for our client, we weren’t sure how to approach the task. We had many questions to answer, and even more questions arose during our research. We had to determine the best language and database to build the product with, how to perform filtering, and even more challenges to solve.
We faced a difficult task but were more than ready for the challenge. Everyone on the Integrant development team is passionately committed to delivering the highest quality results for clients. If we don’t have the answer, we’ll search relentlessly until we find it. Whether building a new site from scratch or migrating a legacy application, we are Java “ninjas” who thrive when solving challenges.
As a result of our research findings, we determined that Java is a natural fit for this project. We’ve made significant progress and are nearing the project’s demo phase.
If you have a business challenge you need help with, we can help. You've come to the right place if you’re looking for seasoned enterprise Java developers. We’d love to work with you, so give us a call today to learn how we can partner together on your next project.