AI and Java: Boost Your Business with a Customized Recommendation Engine

Artificial Intelligence (AI) is one of the hottest tech topics today. Estimates suggest that 77% of the global population uses it in some form, and a recently released report by the IDC projects global spending on AI will double in the next 4 years to $110B annually. AI has already been implanted in our daily lives as Siri, Alexa, search engine algorithms, and various chatbots rely on AI to service us.
The recommendation engine is one hallmark of the numerous digital transformations ushered in by AI and Java. The tech titans Amazon and Netflix pioneered the technology, famously offered a $1M prize to anyone who could improve their recommendation engine by 10%.
The ability to anticipate a customer’s preferences and provide recommendations has become a primary differentiator between digital companies and their legacy counterparts, springing Amazon and Netflix to the cutting edge of their respective industries.
Take Norrøna, a leading brand of outdoor clothing in Scandinavia, which transitioned from wholesale to its first brick-and-mortar store and e-commerce site replete with recommendation engines in 2009. Over the next 10 years, Norrøna grew into over 22 physical stores, generating approximately half of its revenue from direct-to-consumer sales.
In Part 1, the preview article for this series, we discussed the journey of building a Java-based recommendation engine for a client’s e-commerce needs. Considering we had no prior experience with recommendation engines, we underwent a steep learning curve, from discovering the various choices of supporting technologies to determining if we should build an engine from scratch or customize an existing one to how we would eventually train it with data, becoming experts in building machine learning algorithms along the way.
Our initial efforts at building a recommendation engine used content-based filtering, a process that matched user interests with various products based on their previous searches or feedback.
Typically, the algorithms would look for products based on previous interests stored in the user profile and promote them to the user. However, one drawback to content-based recommendation engines is that they lose efficacy for more complex user profiles or when clear and differentiated descriptions are required. We would discover more advanced machine-learning algorithms that comprehensively analyze user interactions to tackle these drawbacks.
In this second article, we showcase the next steps in developing complex recommendation engines and how we integrated AI and Java into our own Java recommendation engine through sophisticated data filtering and enhanced matching capability.
Java and Machine Learning: The Foundation of Smart Recommendations
First, it's essential to understand why we need an enhanced recommendation engine and to briefly differentiate between Java and AI, machine learning, and deep learning.

Artificial intelligence Java projects are on the rise because the premise of AI is to model human intelligence that can mimic our actions and emotions. Humanoid robots, for instance, exhibit numerous attributes of artificial intelligence in their ability to move and replicate the human body.
A subset of AI, machine learning focuses on training algorithms with large datasets to train software to learn from its own "experiences," much like a young child. Deep learning, in turn, is a more complex form of machine learning based on even more advanced techniques using neural networks that mimic our own brains.
As Maruti Techlabs states: "People generally like to be recommended things which they would like, and when they use a site which can relate to his/her choices extremely perfectly, then he/she is bound to visit that site again." Replicating human intelligence recommendation engines provides users with a personalized interface that caters to their interests, ultimately boosting your sales and customer retention.

At this project's outset, one of the foremost questions we had to ask ourselves was whether we should build a Java recommendation engine from scratch for our client. We found a few major reasons why it would be advantageous:
Improve Retention
Effective recommendation engines streamline the user experience, encouraging them to continue using our client’s products.
Increase Purchase Frequency
Recommending products that align with users' interests encourages customers to purchase more products each visit.
Re-purchase Items
A well-built recommendation engine would remind customers to repurchase a product they bought in the past, boosting sales.
Promote a Wider Variety of Products
Finally, a good recommendation engine utilizes the scope and variety of our client’s offerings, engaging the users with a broader array of products.
Supervised vs. Unsupervised Machine Learning
By adopting the artificial intelligence approach to building a recommendation engine, we had to address the two primary types of filtering: supervised vs. unsupervised machine learning.
Supervised filtering is about feeding the machine learning algorithm with input data and providing an expected output, anticipating it will learn to detect underlying patterns in labeled data, like determining what category a news article belongs to.
On the other hand, unsupervised filtering receives unlabeled data and is left to form its own patterns unsupervised by humans. After weighing both options, we found unsupervised filtering was the best choice for our client and served as a great learning opportunity.
Facebook is a pioneer in machine learning and recommendation engines. The company is well-known for its use of Java and machine learning to collect data and recommend content to its billions of users.
It uses hundreds of parameters and key performance indicators to anticipate and collect data on user interactions, factoring in everything from scrolling, comments, likes, shares, and posts to external apps, polls, or advertisements into its neural networks.
Complex machine learning algorithms are on the bleeding edge of e-commerce and social media technology and can serve as a key differentiator from more antiquated companies.
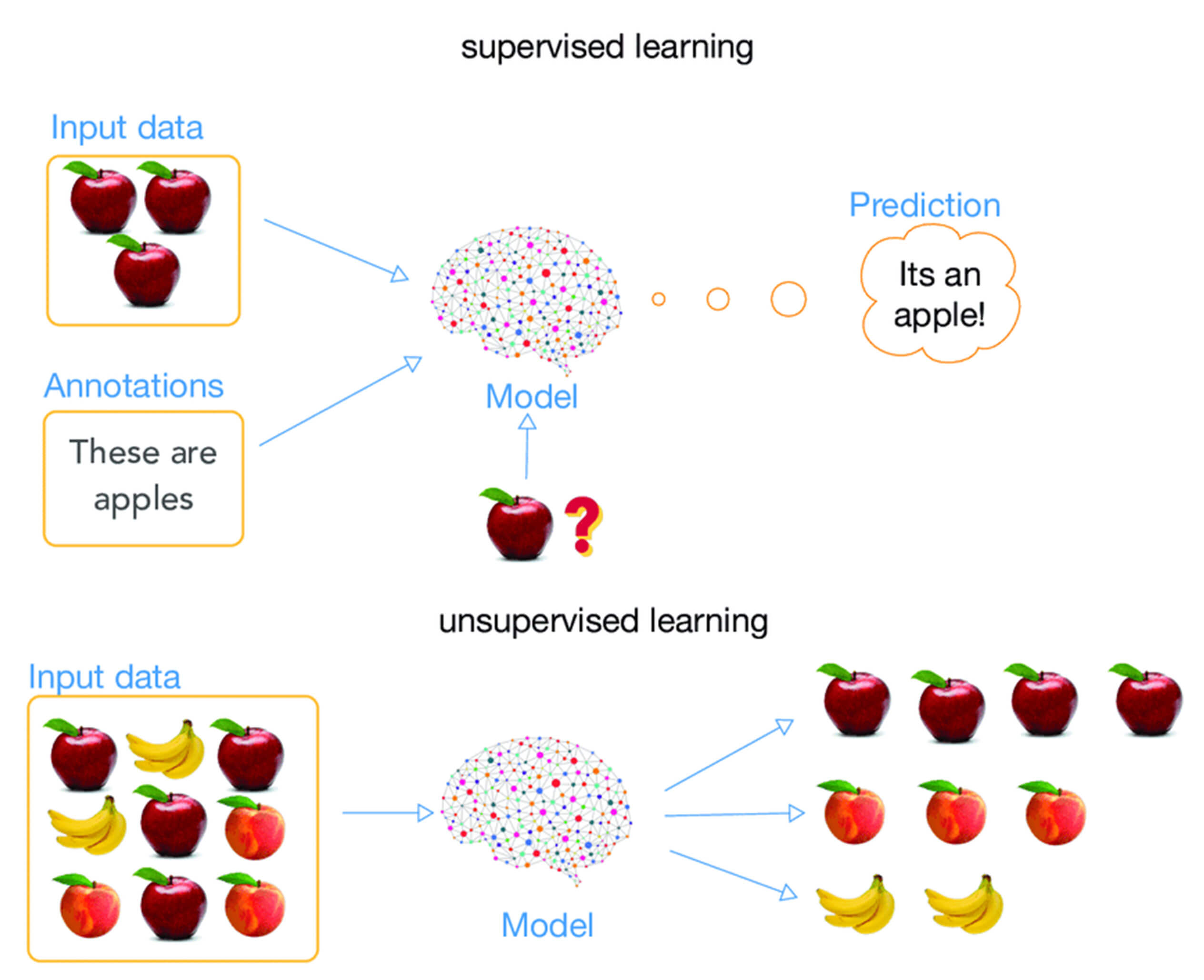
So, the question becomes this: What methodology would we use to provide users recommendations based on their preferences?
We could use two types of data: implicit and explicit feedback. When a new user registers, implicit feedback is the data that they provide interacting with the site or application, like the information they read, the duration of their visit, any products they interact with, what content they view, the links they visit, and other data that is fed into predictive algorithms.
Explicit feedback is any information the user provides in response to a request or question. However, we needed a baseline to work with before we could use more complex AI and Java recommendation techniques. How could we train a system without previous user knowledge to learn their unique preferences? This is one of the challenges we faced in determining how to prepare our recommendation engine.
Cosine Similarity: The Secret to Personalized Recommendations
Fortunately, we landed upon an ingenious solution called cosine similarity. Cosine similarity is a technique used in machine learning textual analysis that measures the similarity of two documents using word frequency instead of text length. Selva Prabhakaran explains it as follows:
"Mathematically, it measures the cosine of the angle between two vectors projected in a multi-dimensional space. The cosine similarity is advantageous because even if the two similar documents are far apart by the Euclidean distance (due to the size of the document), chances are they may still be oriented closer together. The smaller the angle, the higher the cosine similarity."
To provide a brief overview, in cosine similarity, the characteristics of two documents are projected as a vector in multi-dimensional space. The magnitude of the vector correlates to the number of times a word appears, while the angle correlates to the frequency at which the word appears in the text, which is independent of the actual length of the text.
The power of cosine similarity is the ability to compare how similar two texts are using the cosine of the angle between their vectors, ascertaining an accurate result regardless of the difference in actual length or the magnitude of two documents. 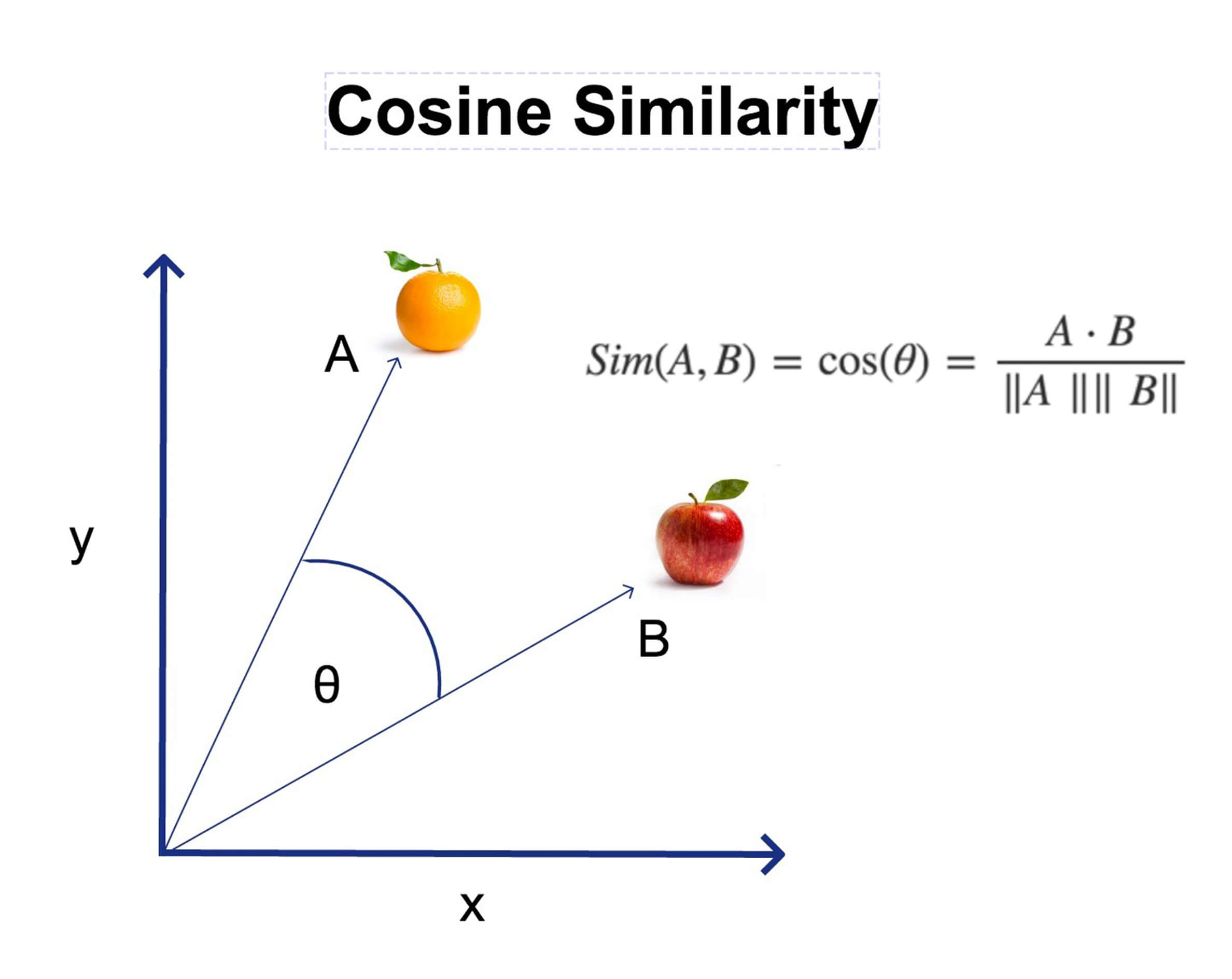
The magic behind the cosine similarity algorithm is that it assigns a probability for a single term and determines the similarity of those words based on the frequency in which it appears. In our test case, we used a database of 60,000 unique English words and assigned them a vector corresponding to each word's frequency and the number of times it appears.
Adopting this methodology, we could derive the similarity of the content of various documents using the cosine of the angle between their respective vectors. The smaller the angle, the greater the cosine similarity.
For the database administrator using our AI and Java recommendation engine, we offer the ability to weigh user interactions for their impact on the recommendation engine. For instance, you can determine that when a user "saves content for later," it has a certain weight in determining the predictive algorithm.
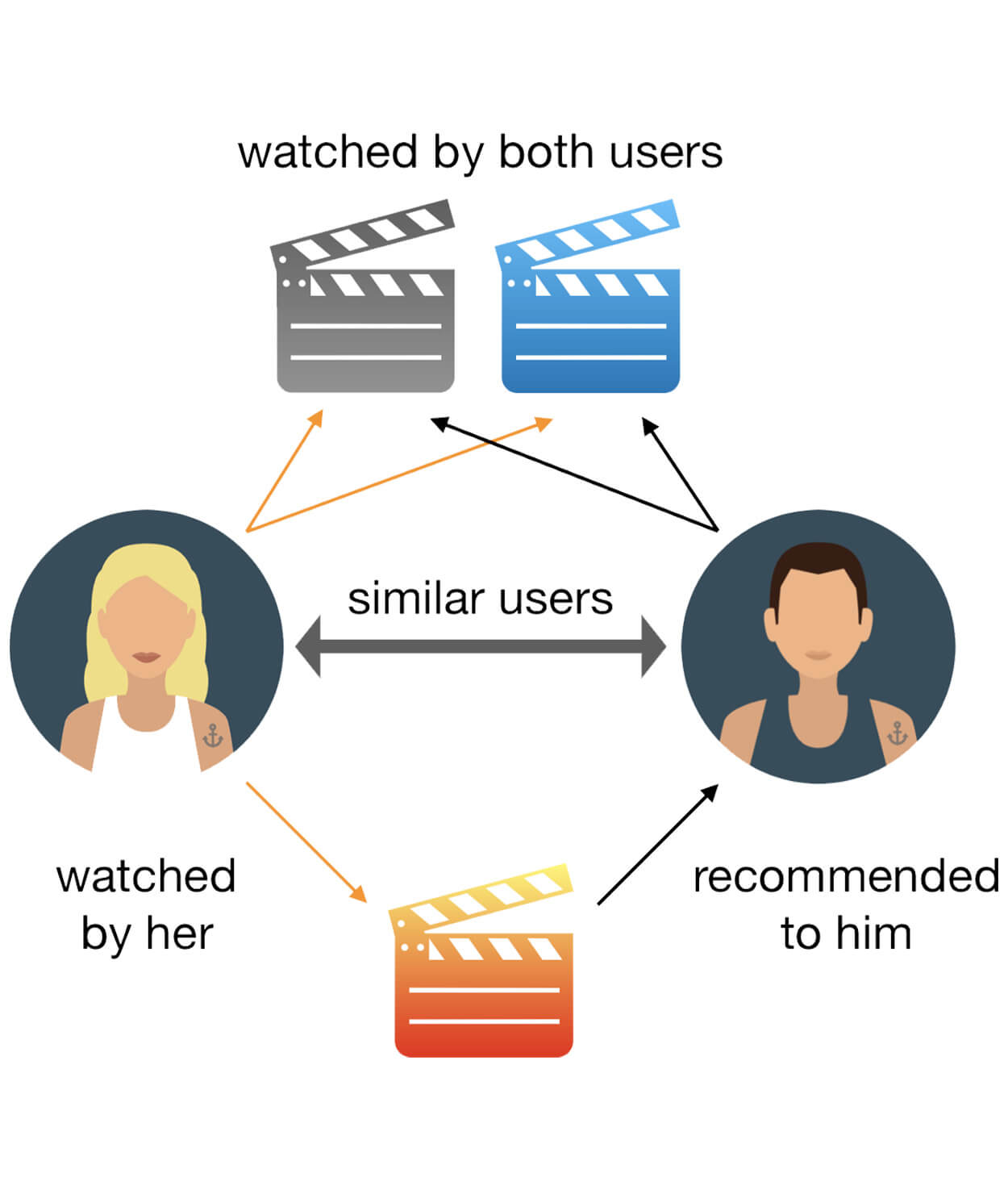
This interaction becomes a part of a set of predicted actions the user will be expected to perform, providing recommendations based on that data.
We are currently experimenting with a movie database to test the recommendation engine. For example, if a user likes watching dramas, they will be assigned a certain weight by our recommendation engine when they add a movie of this genre to the watchlist. Then, if a customer happens to add a comedy movie to the watchlist, we don't automatically assume they have switched interests.
Furthermore, by utilizing AI and Java, we trained the recommendation engine to assign specific numbers for weighted actions: "watching a movie" may be equivalent to a 20 while "adding a movie to the watchlist" might be assigned a 5, thus making the algorithm more precise. By incorporating large datasets and measuring these aggregated and weighted interactions, the cosine similarity algorithm gave us new and exciting insights into creating effective recommendation engines.
Next Steps
When we started building a Java and AI-based recommendation engine, we had no idea the challenges we were up against. However, through trial and error, we have stretched ourselves and gained amazing new insights and discoveries that have made us stronger as a team.
In the process, we learned how recommendation engines work, the best ways to filter and test data, the differences between supervised vs. unsupervised machine learning, and how to train machine learning algorithms to learn unsupervised.
Our goal is to continue using the movie database test platform to further develop our skills in making accurate predictions about customer preferences. We’ve become more advanced in understanding how to filter and weigh datasets through cosine similarity, enabling enhanced matching capabilities for cutting-edge recommendation engines.
We plan to continue strengthening our algorithms with large datasets that will predict sophisticated patterns and rationalize anomalies or variations in user behavior.
Does your business need a recommendation engine to increase customer retention and boost sales? Are you interested in harnessing the benefits of AI and machine learning-based problem-solving to real business challenges?
Suppose you’re looking for seasoned, enterprise-grade Java developers with experience building and testing Java and machine learning algorithms. In that case, we’d be more than happy to share a demo of our work.
Call us today to discover how we can partner on your next project!